The Data Is/Are In
This blog post was originally published on my other blog, AnthonyTeacher.com
Recently, it has come to my attention that I use data as a singular noun, as in “The data is nominal” rather than the plural Latinate form that it technically is, as in “The data are nominal.” To those who brought it to my attention, it is a simple mistake. Fix it. Move on.
But, hold up. I’m not so sure about that. I do not like my natural language use corrected. I will use singular they in writing. I will use so as an adverbial connector while speaking. And, dammit, I will use data in the singular.
Is this just my youthful rebellious spirit? Am I on the vanguard of language change? Am I right? Are they wrong? The answer, as you can guess is yes and no. Both “data is” and “data are” seem acceptable. Here’s the evidence:
1. Twitter
I first turned to Twitter with a poll.
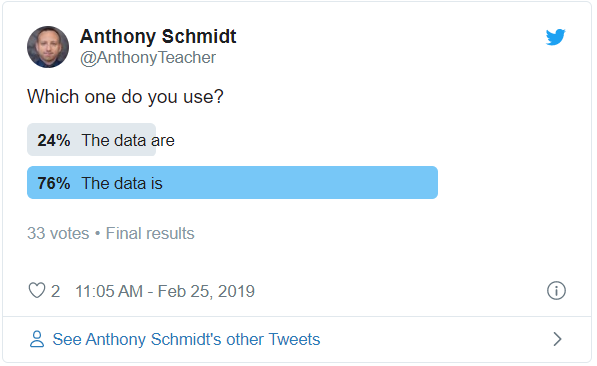
Validation! But, I wanted a more reliable data source, so I began looking at more scientific linguistics tools.
2. Google N-Gram Viewer
The Google N-Gram viewer (see graph below) tells me that, although “data are” is more common, “data is” is also common and has been rapidly increasing in usage in books since the late 1940s. Interestingly, “data are” skyrocketed the 1970s and peaked in the early 1980s (when I was born) and has been in free fall since then. “Data is” hit a small peak around 2000, when I was in college and probably was exposed to more data-based ideas. Similar to “data are,” “data is” has been in decline (I have no guess as to why) and now they are both similar in frequency.
The conclusion here is that, although “data are” once reigned supreme and “data is” has climbed slowly in popularity, they have been able to literally meet each other in the middle.

3. Corpus of Contemporary American English (COCA)
A general search of COCA tells me the following:
| FORM | FREQUENCY | EXAMPLE |
| data were | 4830 | Unfortunately, they did not analyze the impact of fees, as all data were net of fees… |
| data are | 3088 | These data are sensitive and consumers have a right to decide whether or not they can be… |
| data is | 2069 | …but the resulting data is complex and messy. |
| data was | 1075 | Most of the data was culled from studies conducted from the mid-1990s forward at sites in Illinois, Indiana… |
One thing the prompted me to do this research was the use of “data is/are” in academic contexts, so a little more searching in COCA revealed the following:
- “Data is” is 3.8 times more common in academic texts than other genres
- “Data are” is is 16.8 times more common in academic texts.
- “Data were” is 88.9 times more common in academic texts. In fact, this phrase was quite rare in other genres.
- “Data was” is 10.8 times more common.
The conclusion from COCA is similar to the conclusion from Google’s N-Gram viewer: “data are” is more common, especially in academic texts, but “data is” is also common, even in academic texts.
4. Other Corpora
Have you visited the BYU corpus page lately? A few years ago, it was dominated by COCA and the BNC, but it has grown quite a bit since then and we have our choice of corpora ranging from News on the Web, Wikipedia, and even TV and Movie corpora. I chose three to do a quick comparison of “data are/is”.
| Source | “data are/were” Frequency | “data is/was” Frequency |
| GloWbe | 32 / 24 | 654 / 206 |
| TV Corpus | 16 / 12 | 327 / 103 |
| News on the Web | 11,728 / 4,594 | 83,123 /18,782 |
What this data suggests is that “data is” may have grown in tandem with growth in the media, especially online media. This is evident from the higher frequency in the more informal corpora above and the peaks around the year 2000. This growth likely bled over into academic usage as more people were exposed to or participated in these newer forms of communication. However, it is important to recall that the evidence shows “data” as a singular noun existed prior to that growth, too. The growth in media likely amplified the movement of “data is” into common usage.
5. Latinate Cousins
“Data” is not the only plural word used as singular: agenda, bacteria, criteria, media. These are all technically plural forms but often used in the singular. Here is how they are used (from COCA):
| Term | “are / were” frequency | “is / was” frequency |
| Agenda | 61 / 34 | 736 / 258 |
| Bacteria | 338 / 156 | 108 / 37 |
| Criteria | 448 / 457 | 119 / 80 |
| Media | 1060 / 376 | 1655 / 463 |
And here is their growth from Google N-Gram Viewer:

6. Is it a British thing?
I love British English and its quirky grammar and vocabulary, like “government are” rather than the American “government is”. So maybe the “data are/is” thing is a holdover from British English since they do prefer plural forms. Interestingly, looking at the British National Corpus, “data are” and “data is” are almost equally as frequent (491 vs 452, respectively). Looking at just the US and GB dialect forms in the GloWbe Corpus reinforced this. In fact, “data is” was more common than “data are” for all inner-circle and outer-circle English varieties:

7. PLOS One
For my last check, I used AntCorGen to generate a corpus of 300 results sections from various peer-reviewed journals that are part of PLOS One and then ran a frequency search for “data are” and “data is”. The results were unsurprising: 72 for “data are” and 69 for “data is”. While “data are” had higher frequency in total, “data is” had greater range (greater representation in more than 1 text rather than frequent use in single text): 40 vs 30.
8. Cognitive Linguistics
Thus far, I have explained “data” in the singular sense as a side effect of media growth. However, I think this is neither a fully accurate nor fully plausible explanation. So, what is another way it can be explained? One way is through a cognitive linguistic understanding of “data”. In other words, how is “data” represented in the mind? Is “data” conceived of as numerous individual numbers or as a singular set of numbers? Is “data” the part or the whole? I’d argue that, since humans tend towards gestalt grouping, when we speak of data, we are not speaking of figures or numbers or even datums. We are, instead, referring to a singular group or body of information. This mental representation then, when reflected in our lexicogrammar, takes the singular form: “the set is,” “the information is”.
Limitations
I searched mainly for present and some past tense forms of the be verb. I did not, however, check agreement with other common collocating verbs such as show, indicate, suggest, etc.
Conclusion
My exploration through the data has confirmed my original hunch: both forms are acceptable and “data is” has been growing in popularity, growth which has been concomitant with the growth of the media. Furthermore, as data has become more important in our society, it has naturally taken on a singular cognitive gestalt representation.
What does this mean for my own writing? I will continue to use the singular form of data and will proudly point any naysayers to its evidence because the data is in and it clearly shows “data is” is OK!
Anthony Schmidt
Data Scientist
My research interests include data science and education. I focus on statistics, research methods, data visualization, and machine learning.